Existing large language models struggle to support numerous low-resource languages, particularly the extremely low-resource ones, for which there is minimal training data available for effective parameter updating. We thus investigate whether LLMs can learn a new language on the fly solely through prompting.
To study this question, we collect a research suite for Zhuang (壮语, Vahcuengh), a language supported by no LLMs currently. We introduce DiPMT++, a framework for adapting LLMs to unseen languages by in-context learning. Using a dictionary and 5K parallel sentences only, DiPMT++ significantly enhances the performance of GPT-4 from 0 to 16 BLEU for Chinese-to-Zhuang translation and achieves 32 BLEU for Zhuang-to-Chinese translation. We also validate the effectiveness of our framework on Kalamang, another unseen language.
Furthermore, we demonstrate the practical utility of DiPMT++ in aiding non-native speakers in translating completely unseen languages, which could contribute to the preservation of linguistic diversity.
We present ZhuangBench, the first NLP research suite for Zhuang, consisting of a Zhuang-Chinese dictionary, a Zhuang-Chinese parallel corpus, and a Zhuang-Chinese translation test set. It can be used for various NLP tasks. Here, we especially focus on the task of performing Zhuang-Chinese translation using the dictionary and parallel corpus.
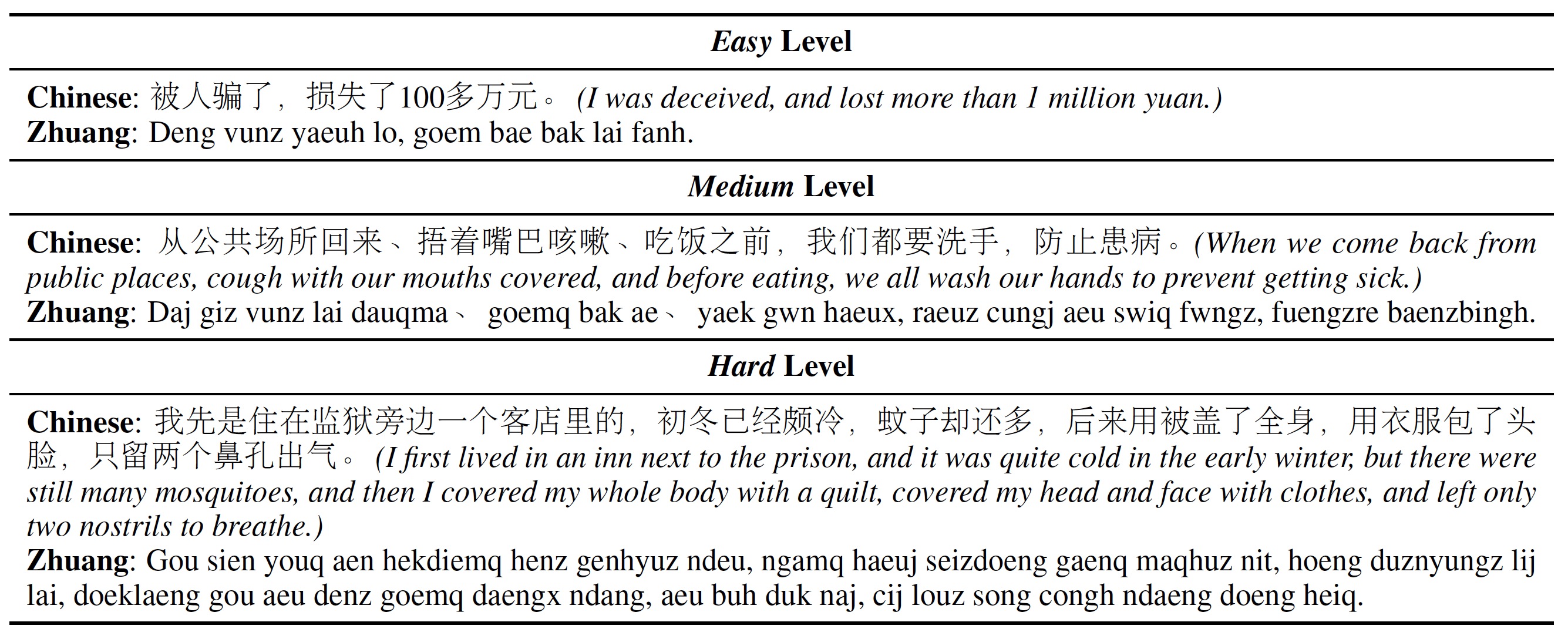
Examples of three difficulty levels in ZhuangBench
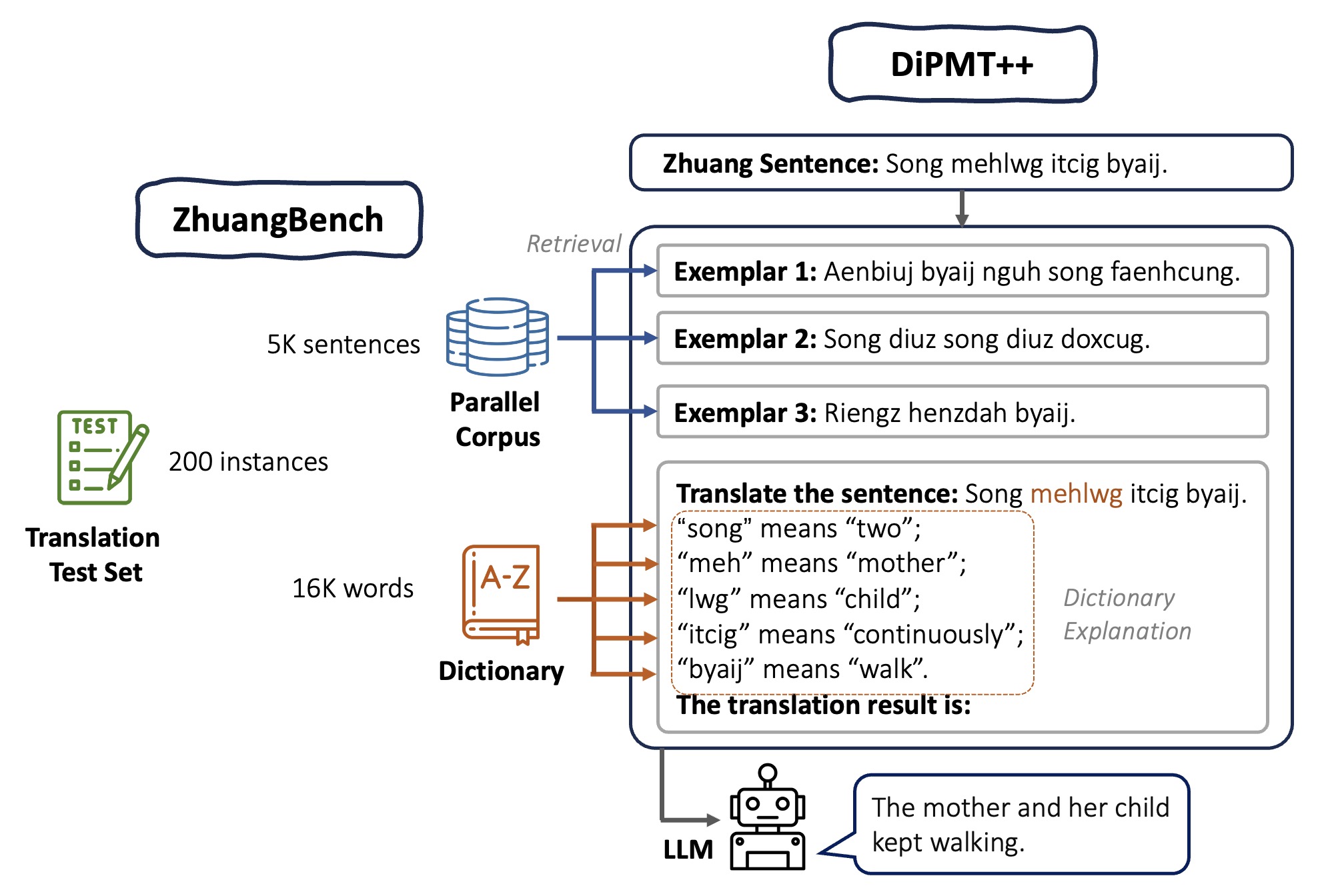
We introduce DiPMT++, a language-agnostic framework to adapt LLMs to an unseen language efficiently. It can serve as a strong baseline for the machine translation task in ZhuangBench.
Our method is built upon DiPMT, a prompting-based method for low-resource language translation. Given a source sentence, the model looks up in the dictionary for the meaning of rare words and adds them to the prompt directly with the format in this context, the word “[source word]” means “[target word]”.
DiPMT is designed for languages that current models perform moderately well (10 - 30 BLEU scores). We make extensions to the DIPMT framework so that it can be applied to extremely low-resource languages.
Following DIPMT, we cast the on-the-fly machine translation as an ICL task and incorporate knowledge from bilingual dictionaries. DiPMT++ makes two key modifications to DIPMT as follows.
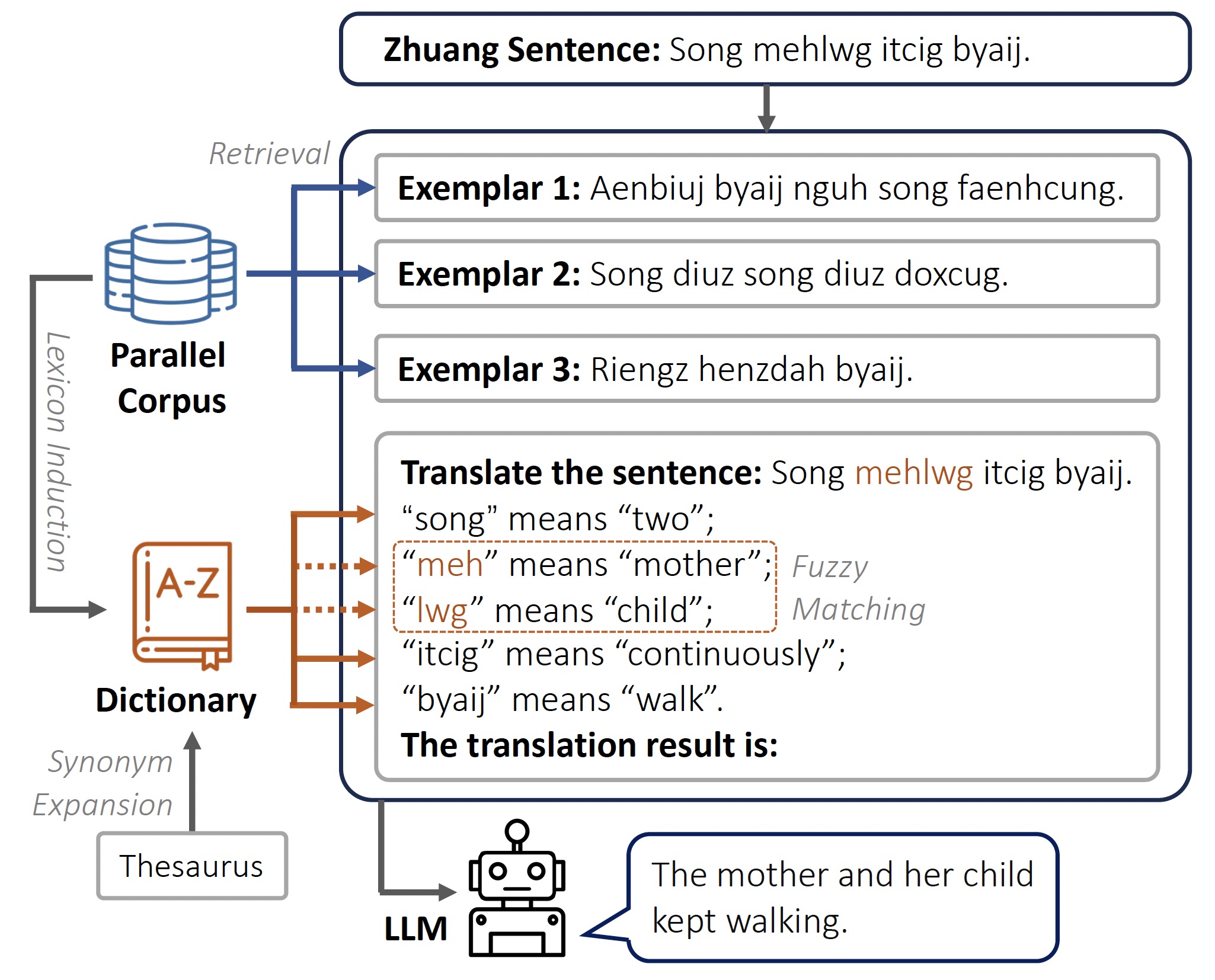
Illustration of DiPMT++
We compare our method with the following baselines:
We report the BLEU and chrF scores of different methods on the ZhuangBench test set.
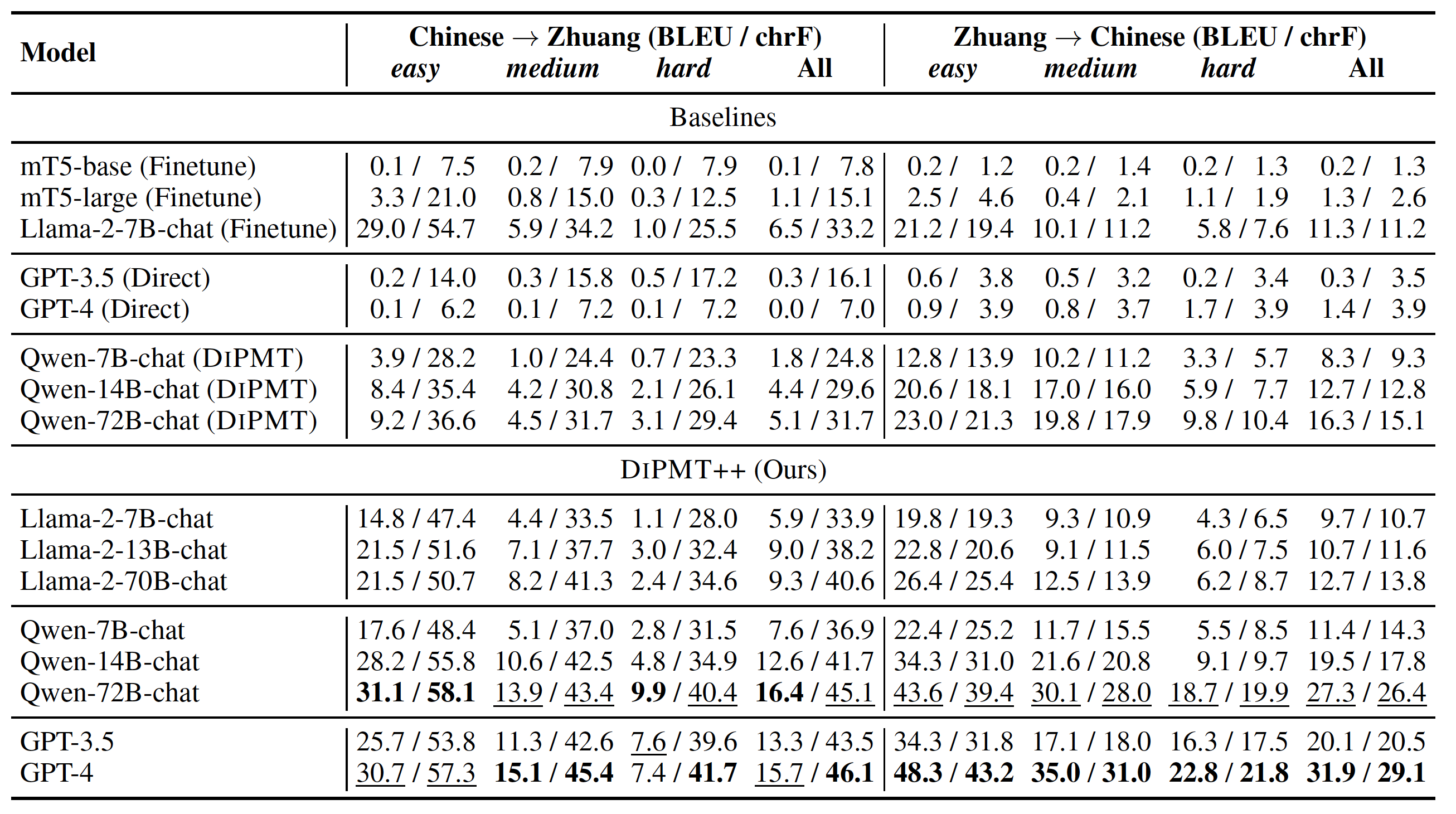
Results of different methods on ZhuangBench
Finetuning vs. Prompting: Compared to the high expense of finetuning, prompting with DiPMT++ requires no training while delivering comparable or even superior performance when combined with larger models.
DiPMT++ vs. DiPMT: Although useful for mid-source languages, the original DIPMT has limited ability to assist LLMs in understanding a completely new language. After introducing two simple extensions, DiPMT++ activate the reasoning ability of LLMs and greatly boost the performance.
Model Scale: Regarding model scales, we observe that the performance steadily improves with the increase of model parameters for Llama-2 and Qwen. It is worth noting that the open-source Qwen-72B-chat performs comparably to the closed-source GPT-4 on the Chinese-to-Zhuang task, which is an encouraging result for more transparent and reproducible research on low-resource NLP.
It is extremely hard to identify a language completely unseen by current LLMs and collect enough resources for it. Besides ZhuangBench, the only suitable evaluation dataset is MTOB. It consists of translation tasks between English (eng) and Kalamang (kgv), another low-resource language unseen by current LLMs.
DiPMT++ outperforms the baseline in the original paper of MTOB across most settings. This further proves that DiPMT++ is a languageagnostic framework and can adapt to different lowresource languages without extra effort.
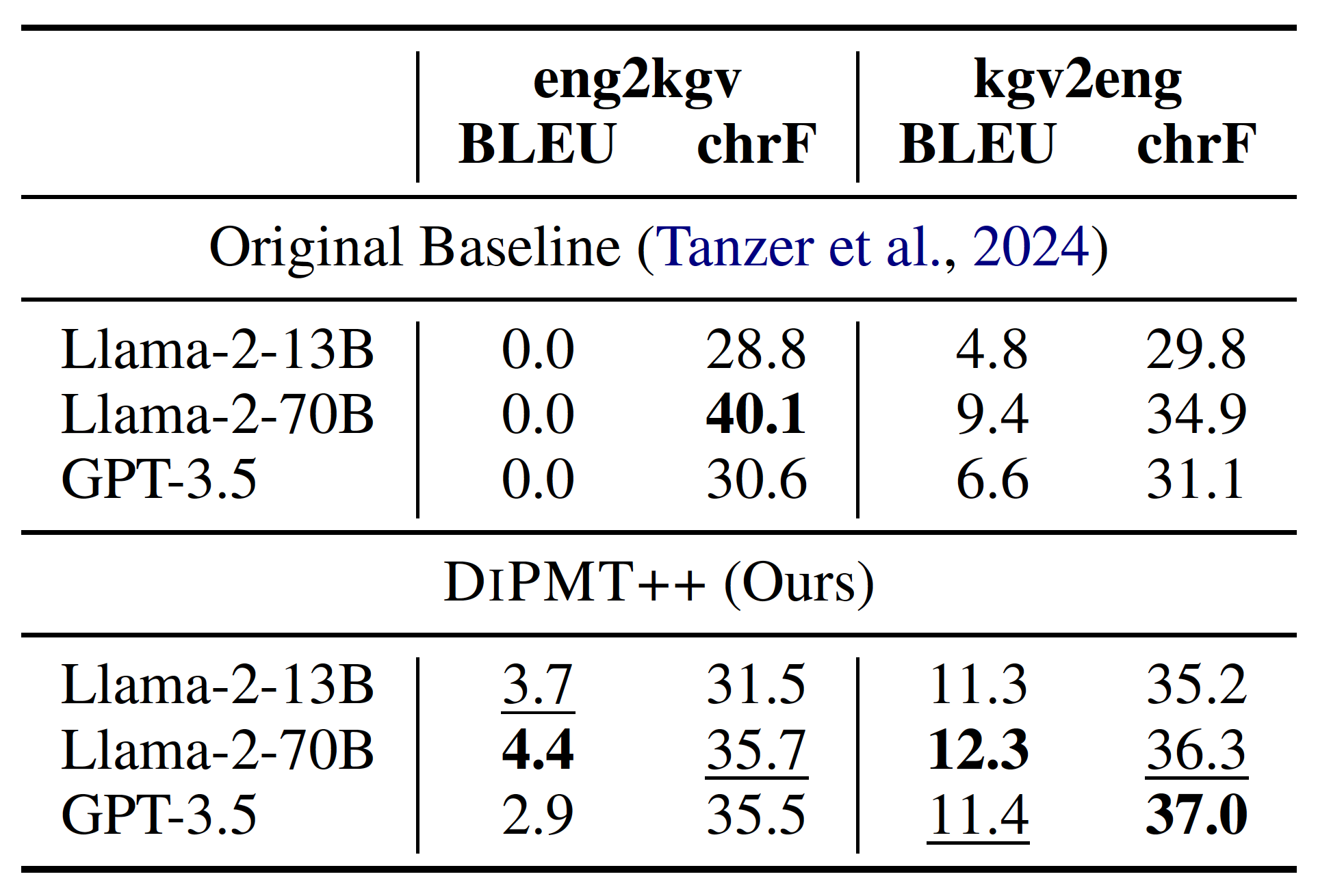
Results of different methods on MTOB
We conduct a user study to demonstrate the effectiveness of DiPMT++ in aiding non-native speakers in translating completely unseen languages. We recruit 6 participants who are native Chinese speakers and have no prior knowledge of Zhuang. The results show that we can use LLMs to assist humans in understanding an extremely low-resource language, even if both the LLMs and the humans have no prior knowledge about this language.
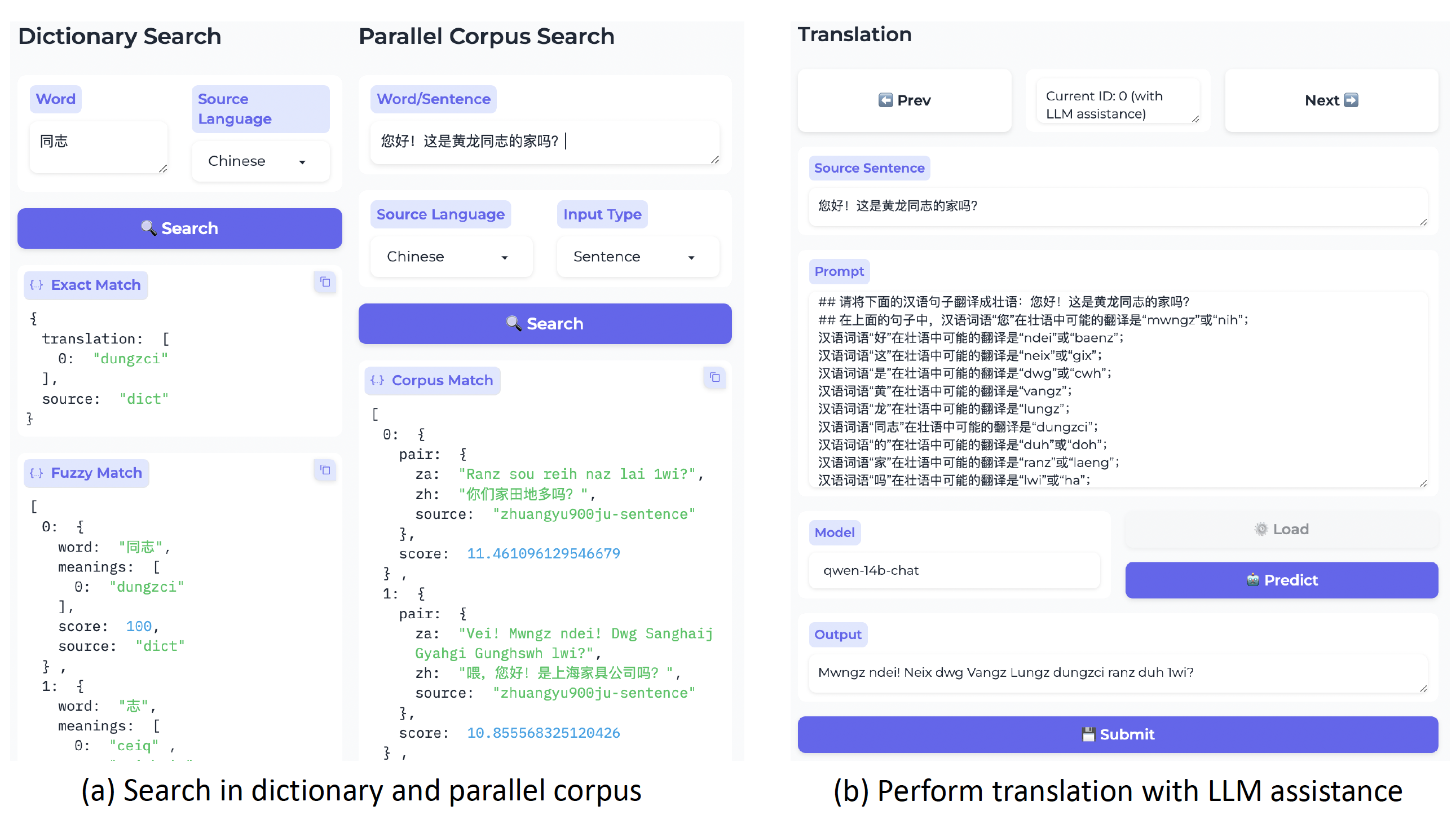
Interface for LLM assisted translation
We compare three settings:
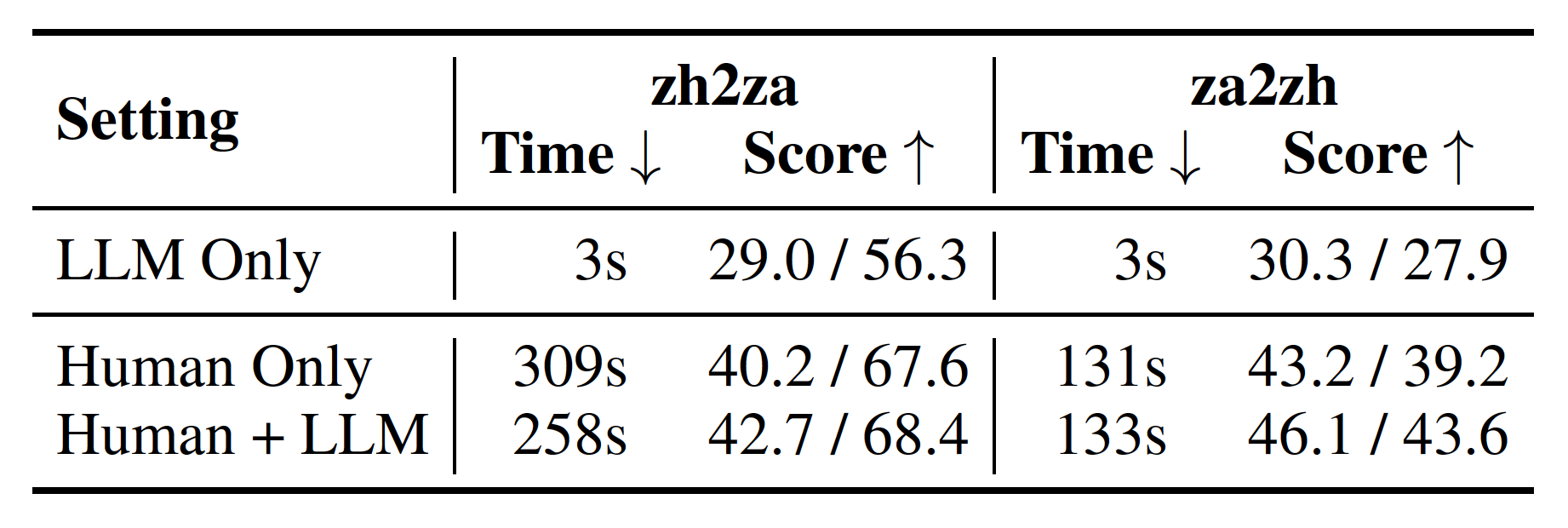
Average time for translating an instance and the translation performance in the user study.
The numbers in the Score column are BLEU and chrF.
Providing initial translation output from the LLM yields improvement in human translation quality. For Chinese-to-Zhuang translation, the LLM helps increase the human performance by 2.5 BLEU while the improvement is 2.9 BLEU for Zhuang-to-Chinese translation.
The LLM greatly boosts the efficiency of Chinese-to-Zhuang translation. The participants save 17% of their time on average, as they can leverage the LLM’s output rather than crafting translations from scratch.
Besides aiding humans in translation, the LLMs enhanced with the DiPMT++ framework have broader applications for low-resource languages. These include education for underrepresented languages, preservation of endangered languages, and research into historical or extinct languages. We anticipate that by these techniques, researchers can better contribute to the linguistic diversity worldwide.
@article{zhang2024teaching,
title={Teaching Large Language Models an Unseen Language on the Fly},
author={Zhang, Chen and Liu, Xiao and Lin, Jiuheng and Feng, Yansong},
journal={arXiv preprint arXiv:2402.19167},
year={2024}
}